常见问题解答
关于通用功能、故障排除、使用方法等方面的问题回答。
- 通用功能
- RAGFlow与其它RAG产品有何不同?
- RAGFlow 全功能版与轻量版有何不同?
- 哪些嵌入模型可以本地部署?
- 如何查看 RAGFlow 版本?如何解读版本号?
- 为何不使用其他开源向量数据库作为文档引擎?
- demo.ragflow.io 与本地部署的开源 RAGFlow 服务有何不同?
- 为何 RAGFlow 解析文档的时间比 LangChain 更长?
- 为什么 RAGFlow 需要更多的资源?
- RAGFlow支持哪些架构或设备?
- 你们提供用于与第三方应用程序集成的API吗?
- RAGFlow支持流式输出吗?
- RAGFlow支持通过URL分享对话吗?
- RAGFlow支持多轮对话,并根据先前的对话内容作为当前查询的上下文吗?
- AI搜索和AI聊天之间有何区别?
- 问题排查
- 如何从零开始构建RAGFlow镜像?
- 无法访问https://huggingface.co
MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)WARNING: can't find /raglof/rag/res/borker.tm- 网络异常
- 实时同义词功能已禁用,因为没有 Redis 连接
- 为什么我的文档解析停滞在不到�百分之一?
- 为什么我的 PDF 解析在接近完成时停滞,而日志中没有显示任何错误?
- 索引失败
- 如何查看 RAGFlow 的日志?
- 如何检查 RAGFlow 中每个组件的状态?
异常: 无法连接到ES集群- 无法启动ES容器并收到
Elasticsearch did not exit normally { "data": null, "code": 100, "message": "<NotFound '404: Not Found'>"}Ollama - Mistral实例运行于127.0.0.1:11434但无法将Ollama添加为RagFlow模型- 您能提供使用DeepDoc解析PDF或其他文件的示例吗?
FileNotFoundError: [Errno 2] No such file or directory
- 使用方法
通用功能
RAGFlow与其它RAG产品有何不同?
尽管大型语言模型(LLM)在自然语言处理(NLP)方面取得了显著进展,但“输入垃圾输出垃圾”的现状仍然未变。相比之下,RAGFlow 引入了两个独特的特性:
- 精细文档解析:文档解析涉及图像和表格,并且您可以在需要时进行干预。
- 可追溯的回答减少幻觉:您可以信任 RAGFlow 的回答,因为可以查看支持其回答的引用和支持材料。
RAGFlow 全功能版与轻量版有何不同?
每个 RAGFlow 发行版本均有两个版本:
- 轻量版:不包含内置嵌入模型,并在版本名后添加了“-slim”后缀。例如:
infiniflow/ragflow:v0.20.3-slim - 全功能版:包含内置嵌入模型,且版本名称没有后缀。例如:
infiniflow/ragflow:v0.20.3
哪些嵌入模型可以本地部署?
RAGFlow 提供两个 Docker 镜像版本,“v0.20.3-slim”和“v0.20.3”:
infiniflow/ragflow:v0.20.3-slim(默认):不包含嵌入模型的 RAGFlow Docker 镜像。infiniflow/ragflow:v0.20.3:包括以下内置嵌入模型在内的 RAGFlow Docker 镜像:- 内置嵌入模型:
BAAI/bge-large-zh-v1.5maidalun1020/bce-embedding-base_v1
- 您在 RAGFlow UI 中选择后将下载的嵌入模型:
BAAI/bge-base-en-v1.5BAAI/bge-large-en-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5jinaai/jina-embeddings-v2-base-enjinaai/jina-embeddings-v2-small-ennomic-ai/nomic-embed-text-v1.5sentence-transformers/all-MiniLM-L6-v2
- 内置嵌入模型:
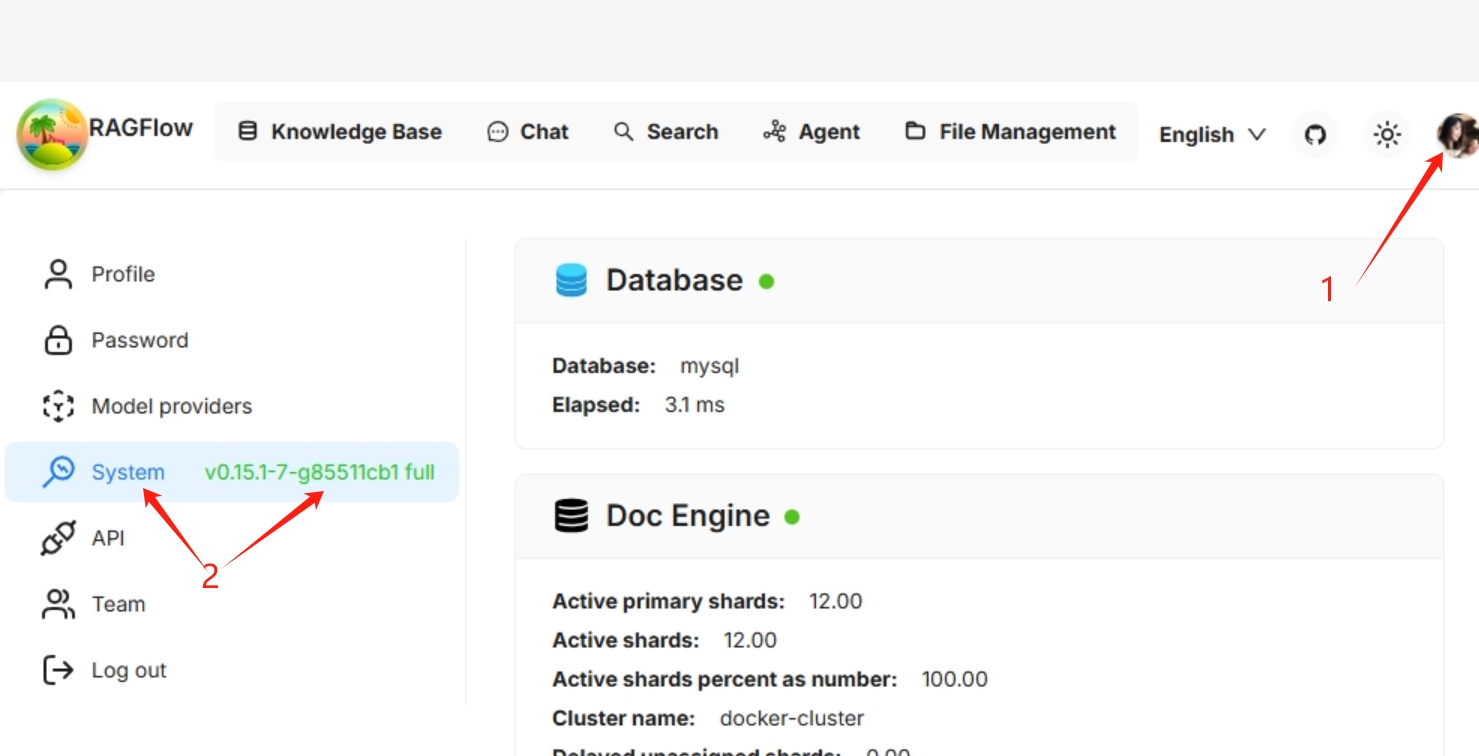
如何查看 RAGFlow 版本?如何解读版本号?
您可以在 UI 的“系统”页面上找到 RAGFlow 版本号:
如果您从源代码构建 RAGFlow,版本号也会出现在系统日志中:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
2025-02-18 10:10:43,835 INFO 1445658 RAGFlow version: v0.15.0-50-g6daae7f2 full
其中:
v0.15.0:官方发布的版本。50:自发布以来的 git 提交次数。g6daae7f2:“g”是前缀,6daae7f2是当前提交 ID 的前七个字符。full/slim:RAGFlow 版本。full:全功能版 RAGFlow。slim:不包含嵌入模型和 Python 包的轻量版。
为何不使用其他开源向量数据库作为文档引擎?
目前,只有 Elasticsearch 和 Infinity 符合 RAGFlow 的混合搜索需求。大多数开源向量数据库仅支持有限的全文搜索功能,并且稀疏嵌入不能替代全文搜索。此外,这些向量数据库缺乏关键特性,如短语搜索和高级排名能力。
由于这些限制,我们从头开发了 Infinity,即面向 AI 的数据库。
demo.ragflow.io 与本地部署的开源 RAGFlow 服务有何不同?
demo.ragflow.io 展示了 RAGFlow Enterprise 的功能。其 DeepDoc 模型使用专有数据预训练,并提供更复杂的团队权限控制。本质上,demo.ragflow.io 是展示即将推出的 SaaS(软件即服务)产品的预览。
您可以部署开源的 RAGFlow 服务并通过 Python 客户端或 RESTful API 调用它。但这在 demo.ragflow.io 中不被支持。
为何 RAGFlow 解析文档的时间比 LangChain 更长?
我们在文档预处理任务(如版面分析、表格结构识别和 OCR)中使用了视觉模型,这增加了额外的时间需求。
为什么 RAGFlow 需要更多的资源?
RAGFlow 内置了一些用于解析文档结构的模型,这是需要更多计算资源的原因。
RAGFlow支持哪些架构或设备?
我们官方支持x86 CPU和nvidia GPU。虽然我们也测试了RAGFlow在ARM64平台上的运行情况,但我们不维护针对ARM的RAGFlow Docker镜像。如果你使用的是ARM平台,请参考此指南构建一个RAGFlow Docker镜像。
你们提供用于与第三方应用程序集成的API吗?
对应的API现在已经可用。更多信息请参见RAGFlow HTTP API 参考或RAGFlow Python API 参考。
RAGFlow支持流式输出吗?
是的,我们支持。在聊天助手和代理中,默认启用了流式输出功能。请注意,您无法通过RAGFlow的UI关闭流式输出。要禁用响应中的流式输出,请使用RAGFlow的Python或RESTful API:
Python:
RESTful:
RAGFlow支持通过URL分享对话吗?
不,此功能目前不受支持。
RAGFlow支持多轮对话,并根据先前的对话内容作为当前查询的上下文吗?
是的,我们支持基于正在进行的会话中现有上下文来增强用户查询:
- 在聊天页面上,将鼠标悬停在所需的助手上方并选择编辑。
- 在弹出的聊天配置窗口中,点击提示引擎选项卡。
- 打开多轮优化开关以启用此功能。
AI搜索和AI聊天之间有何区别?
- AI搜索: 这是一个使用预定义检索策略(基于加权关键词相似度和向量相似度的混合搜索)并与系统默认聊天模型进行的一次性AI对话。它不涉及知识图谱、自动关键词或自动问题等高级RAG策略。检索到的块会列在聊天模型响应的下方。
- AI聊天: 这是一个多轮AI对话,您可以定义自己的检索策略(可以使用加权重排分数来替换混合搜索中的向量相似度),并选择您的聊天模型。在AI聊天中,您还可以为特定情况配置高级RAG策略,如知识图谱、自动关键词和自动问题等。检索到的块不会与答案一同显示。
调试你的聊天助手时,你可以使用AI搜索作为参考来验证你设置中的模型参数和检索策略。
问题排查
如何从零开始构建RAGFlow镜像?
无法访问https://huggingface.co
默认情况下,本地部署的RAGflow会从Huggingface网站下载OCR和嵌入模块。如果您的机器无法访问该站点,则会发生以下错误,并且PDF解析失败:
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
要解决此问题,请使用https://hf-mirror.com
-
停止所有容器并删除相关资源:
cd ragflow/docker/
docker compose down -
在ragflow/docker/.env文件中取消注释以下行:
# HF_ENDPOINT=https://hf-mirror.com -
启动服务器:
docker compose up -d
MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)
此错误表明您的设备无法访问Internet或无法连接到hf-mirror.com。请尝试以下操作:
-
从huggingface.co/InfiniFlow/deepdoc手动下载资源文件并将其保存在本地文件夹~/deepdoc中。
-
在docker-compose.yml文件中添加挂载,例如:
- ~/deepdoc:/ragflow/rag/res/deepdoc
WARNING: can't find /raglof/rag/res/borker.tm
忽略此警告并继续。所有系统警告都可以被忽略。
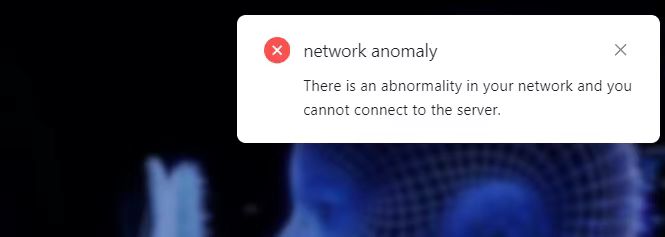
网络异常
您的网络存在异常情况,无法连接到服务器。
除非您的服务器完全初始化,否则您无法登录RAGFlow。运行 docker logs -f ragflow-server。
如果您的系统显示以下信息,则表示服务器成功初始化:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* 正在所有地址上运行(0.0.0.0)
* 正在 http://127.0.0.1:9380 上运行
* 正在 http://x.x.x.x:9380 上运行
INFO:werkzeug:按CTRL+C退出
实时同义词功能已禁用,因为没有 Redis 连接
忽略此警告并继续。可以忽略系统中的所有警告信息。

为什么我的文档解析停滞在不到百分之一?
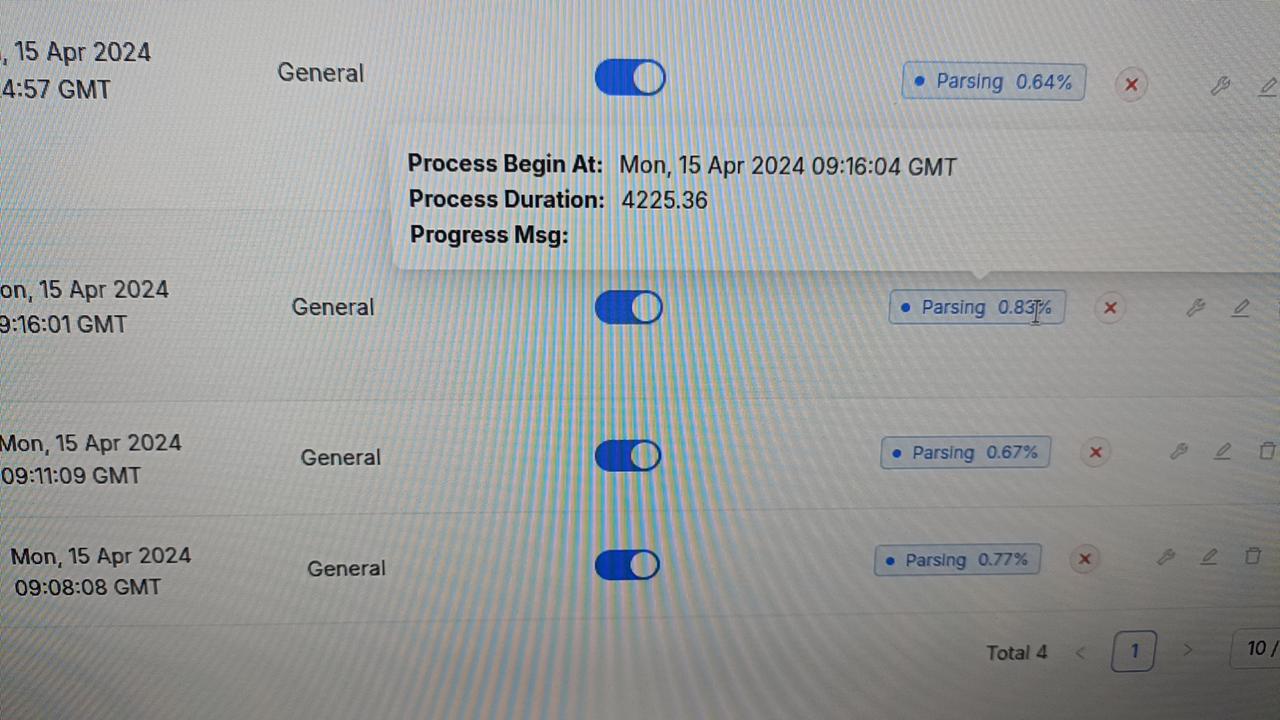
点击“解析状态”栏旁的红色叉号,然后重新启动解析过程以检查问题是否仍然存在。如果问题持续且您的 RAGFlow 部署在本地,请尝试以下操作:
-
检查 RAGFlow 服务器的日志,确认其正常运行:
docker logs -f ragflow-server -
确认 task_executor.py 进程是否存在。
-
确认您的 RAGFlow 服务器能否访问 hf-mirror.com 或 huggingface.com。
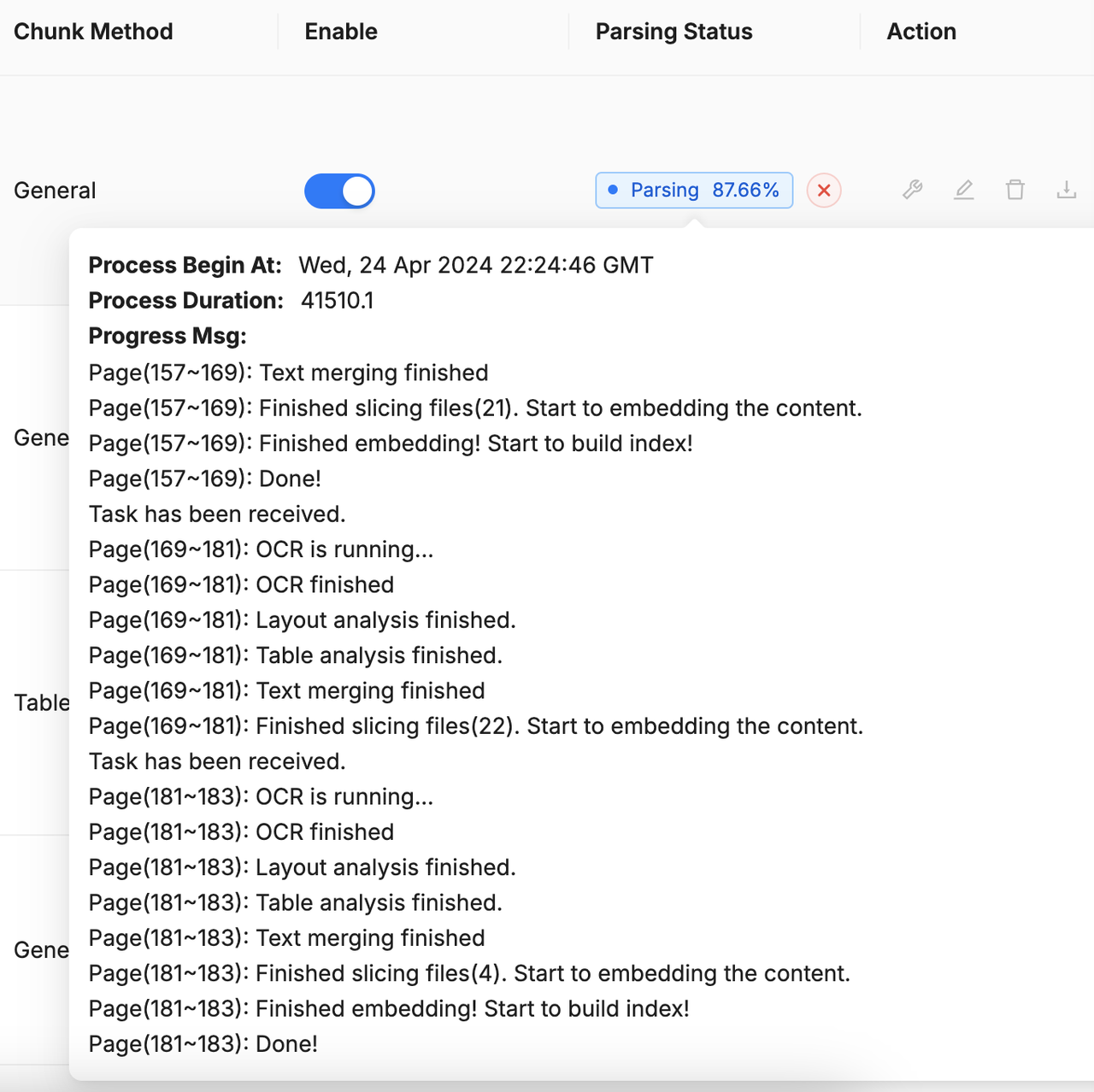
为什么我的 PDF 解析在接近完成时停滞,而日志中没有显示任何错误?
点击“解析状态”栏旁的红色叉号,然后重新启动解析过程以检查问题是否仍然存在。如果问题持续且您的 RAGFlow 部署在本地,则解析进程可能是由于内存不足被杀死的。尝试通过增加 docker/.env 中 MEM_LIMIT 的值来增加内存分配。
请确保重启您的 RAGFlow 服务器以使更改生效!
docker compose stop
docker compose up -d
索引失败
索引失败通常表示 Elasticsearch 服务不可用。
如何查看 RAGFlow 的日志?
tail -f ragflow/docker/ragflow-logs/*.log
如何检查 RAGFlow 中每个组件的状态?
-
检查 Elasticsearch Docker 容器的状态:
$ docker ps以下是一个示例结果:
5bc45806b680 infiniflow/ragflow:latest "./entrypoint.sh" 11 小时前 Up 11 hours 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp ragflow-server
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 小时前 Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
d8c86f06c56b mysql:5.7.18 "docker-entrypoint.s…" 7 天前 Up 16 秒 (healthy) 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp ragflow-mysql
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 周前 Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
参阅 此文档 检查 Elasticsearch 服务的健康状况。
Docker 容器状态并不一定反映服务的状态。您可能会发现即使相应的 Docker 容器正在运行,您的服务仍然处于不健康状态。造成这种情况的原因可能包括网络故障、端口号配置错误或 DNS 问题。
异常: 无法连接到ES集群
-
检查Elasticsearch Docker容器的状态:
$ docker ps健康状态的Elasticsearch组件应该如下所示:
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11小时前 Up 11小时 (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01 -
参考此文档检查Elasticsearch服务的健康状态。
Docker容器的状态不一定反映服务的状态。即使相应的Docker容器正在运行,您的服务可能仍然不健康。这种情况的原因可能是网络故障、端口号配置错误或DNS问题。
- 如果您的容器不断重启,请确保
vm.max_map_count>= 262144,具体操作请参阅此README。如果您希望永久保留更改,则需要在**/etc/sysctl.conf**中更新vm.max_map_count值。请注意,该配置仅适用于Linux。
无法启动ES容器并收到 Elasticsearch did not exit normally
这是因为您忘记了在**/etc/sysctl.conf**中更新vm.max_map_count的值,并且系统重启后更改被重置了。
{ "data": null, "code": 100, "message": "<NotFound '404: Not Found'>"}
您的IP地址或端口号可能不正确。如果您使用的是默认配置,请在浏览器中输入http://<您机器的IP地址>(不是9380,并且不需要端口号!)。这应该可以解决问题。
Ollama - Mistral实例运行于127.0.0.1:11434但无法将Ollama添加为RagFlow模型
正确的Ollama IP地址和端口对于在Ollama中添加模型至关重要:
- 如果您使用的是demo.ragflow.io,请确保托管Ollama的服务器具有公开访问的IP地址。请注意,127.0.0.1不是一个公共可访问的IP地址。
- 如果您本地部署RAGFlow,请确保Ollama和RAGFlow在同一局域网内,并且能够相互通信。
更多详情请参阅在本地部署LLM。
您能提供使用DeepDoc解析PDF或其他文件的示例吗?
是的,我们有。请查看rag/app目录下的Python文件。
FileNotFoundError: [Errno 2] No such file or directory
-
检查MinIO Docker容器的状态:
$ docker ps健康状态的Elasticsearch组件应该如下所示:
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 两周前 Up 11小时 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
参考此文档检查Elasticsearch服务的健康状态。
Docker容器的状态不一定反映服务的状态。即使相应的Docker容器正在运行,您的服务可能仍然不健康。这种情况的原因可能是网络故障、端口号配置错误或DNS问题。
使用方法
如何使用本地部署的LLM运行RAGFlow?
您可以使用Ollama或Xinference来部署本地LLM。更多信息请参阅此处。
如何添加不受支持的LLM?
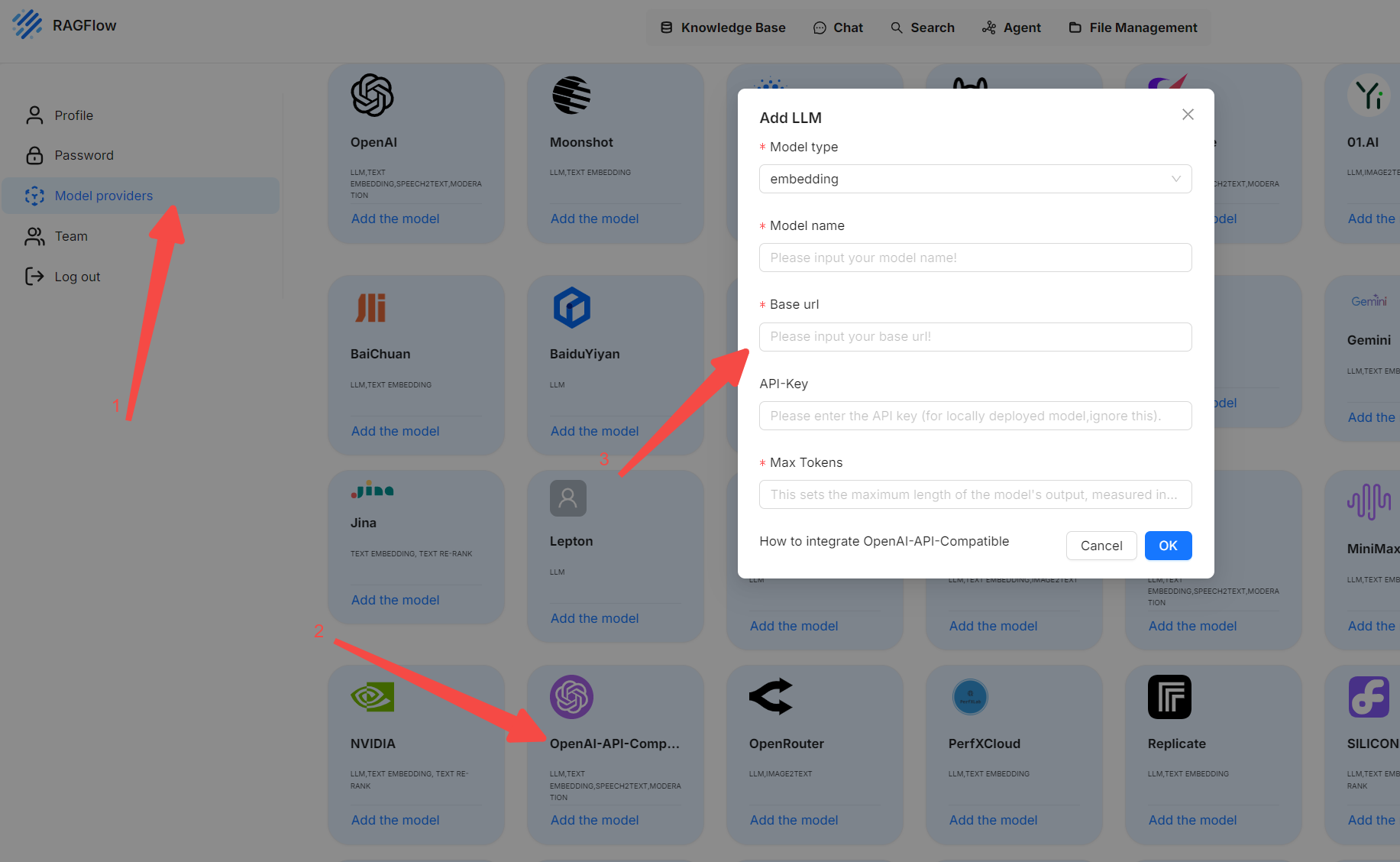
如果您的模型目前不受支持,但其API与OpenAI兼容,请在Model providers页面上点击 OpenAI-API-Compatible来配置您的模型:
如何将RAGFlow与Ollama集成?
- 如果您本地部署了RAGFlow,请确保您的RAGFlow和Ollama在同一局域网内。
- 如果您使用的是我们的在线演示,那么请确保您的Ollama服务器的IP地址是公开可访问的。
更多信息请参阅此处。
如何更改文件大小限制?
对于本地部署的RAGFlow:每次上传的总文件大小限制为1GB,批量上传限制为32个文件。没有单个账号内的总文件数量上限。要更新此1GB文件大小限制:
- 在 docker/.env 文件中取消注释
# MAX_CONTENT_LENGTH=1073741824,根据需要调整数值,并注意1073741824代表的是1GB字节。 - 如果你在 docker/.env 中更新了
MAX_CONTENT_LENGTH的值,请确保相应地在 nginx/nginx.conf 中更新client_max_body_size。
手动更改批量上传限制为32文件的数值不被推荐。然而,如果你使用RAGFlow的HTTP API或Python SDK进行文件上传,则此32文件的批量上传限制将自动移除。
错误:输入长度范围应为 [1, 30000]��
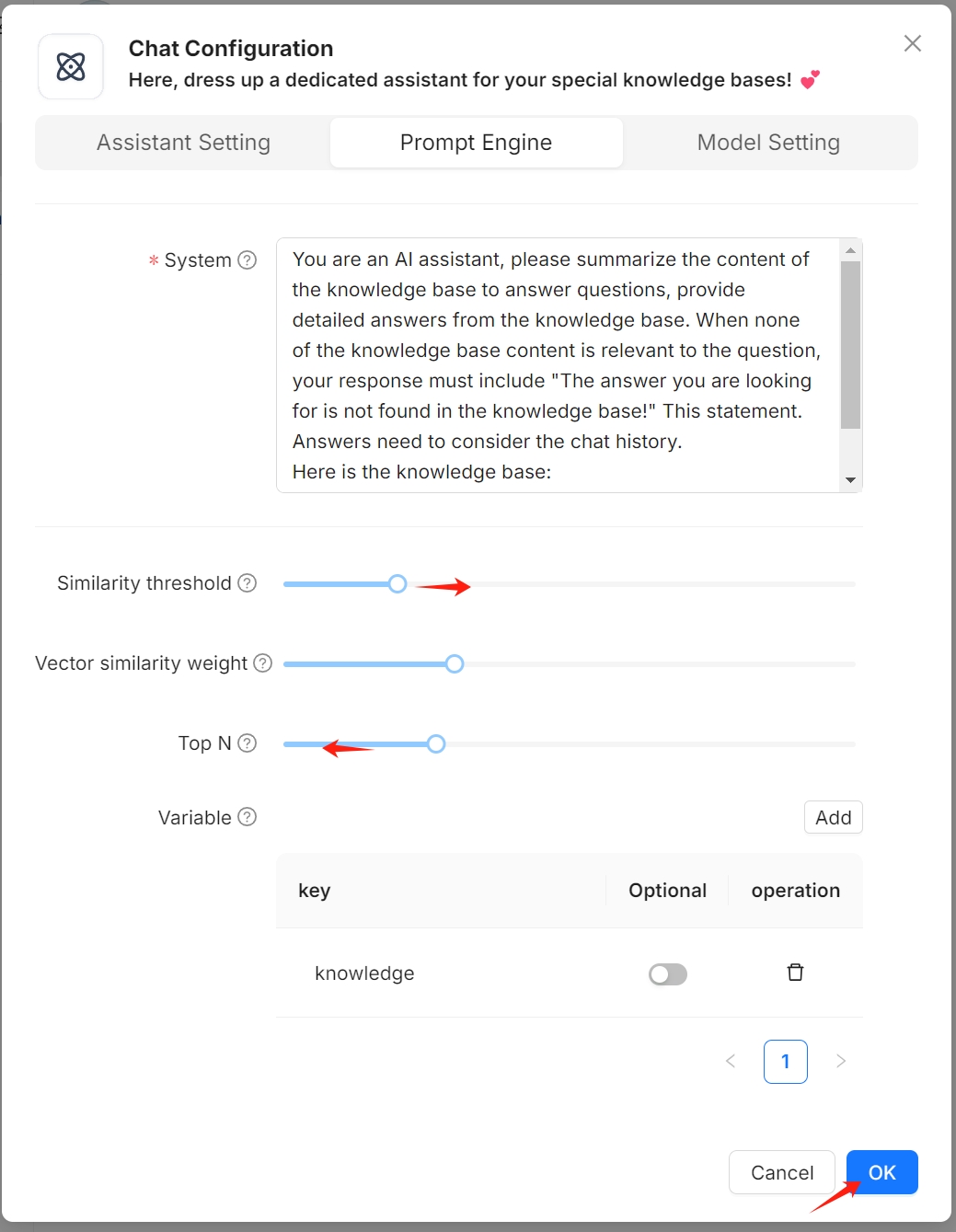
此错误发生的原因是与你的搜索标准匹配的块太多。尝试降低 TopN 并增加 Similarity threshold 来解决这个问题:
- 点击页面顶部中间的“Chat”。
- 右键点击所需的对话 > “编辑” > “Prompt engine”
- 减少 TopN 和/或提高 Similarity threshold。
- 单击“确定”以确认更改。
如何为第三方应用程序获取API密钥?
参见 获取RAGFlow API密钥。
如何升级RAGFlow?
有关更多详细信息,请参阅 升级RAGFlow。
如何将文档引擎切换到Infinity?
要从Elasticsearch切换为Infinity:
-
停止所有运行中的容器:
$ docker compose -f docker/docker-compose.yml down -v
使用 -v 选项将删除所有的Docker容器卷,并清除现有的数据。
-
在 docker/.env 文件中设置
DOC_ENGINE=${DOC_ENGINE:-infinity} -
重启你的Docker镜像:
$ docker compose -f docker-compose.yml up -d
我上传的文件在RAGFlow的图像中存储在哪里?
所有上传的文件都存放在Minio,这是RAGFlow的对象存储解决方案。例如,如果你直接将文件上传到知识库,则它位于 <knowledgebase_id>/filename。
如何调整批量大小以优化文档解析和嵌入?
你可以通过设置环境变量 DOC_BULK_SIZE 和 EMBEDDING_BATCH_SIZE 来控制文档解析和嵌入的批量大小。增加这些值可能会提高大规模数据处理的速度,但也会增加内存使用量。请根据你的硬件资源进行调整。