加速回答
一个检查列表来加快问题的回答速度。
请注意,某些设置可能会消耗大量时间。如果您经常发现问题回答耗时较多,请参考以下检查清单:
- 在“聊天配置”对话框的“提示引擎”选项卡中,关闭“多轮优化”,将减少从LLM获取答案所需的时间。
- 在“聊天配置”对话框的“提示引擎”选项卡中,留空“重排序模型”字段可以显著降低检索时间。
- 使用重排序模型时,请确保拥有一块GPU以加速处理;否则,重排序过程将会变得极其缓慢。
注意
请注意,在某些情况下重排序模型是必不可少的。速度与性能之间总是存在权衡关系;您需要根据具体情况权衡利弊。
- 在“聊天配置”对话框的“助手设置”选项卡中,关闭“关键词分析”,将减少从LLM获取答案所需的时间。
- 与您的聊天助手交流时,请点击当前对话上方的灯泡图标,并在弹出窗口中向下滚动查看每个任务所用时间:
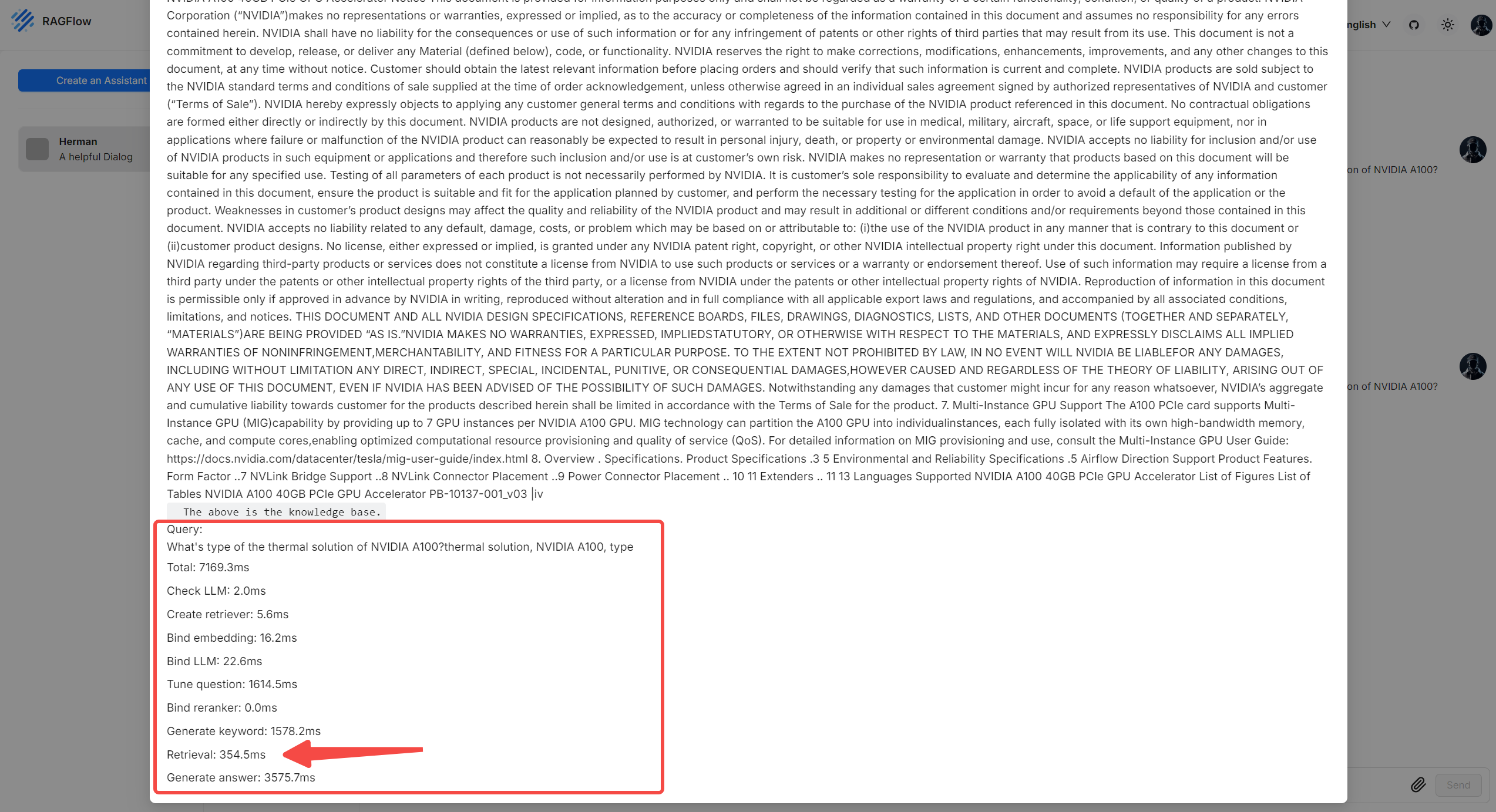
| 项目名称 | 描述 |
|---|---|
| 总计 | 包括片段检索和答案生成在内的本次对话轮次总耗时。 |
| 检查LLM | 验证指定LLM所需的时间。 |
| 创建检索器 | 创建一个片段检索器所用时间。 |
| 初始化嵌入模型 | 初始化一个嵌入模型实例所用时间。 |
| 初始化LLM | 初始化一个LLM实例所用时间。 |
| 优化问题 | 使用多轮对话上下文优化用户查询所需的时间。 |
| 初始化重排序器 | 初始化用于片段检索的重排序器模型实例所需的时间。 |
| 提取关键词 | 从用户查询中提取关键词所需的时间。 |
| 检索 | 获取片段所用时间。 |
| 生成答案 | 生成答案所用时间。 |